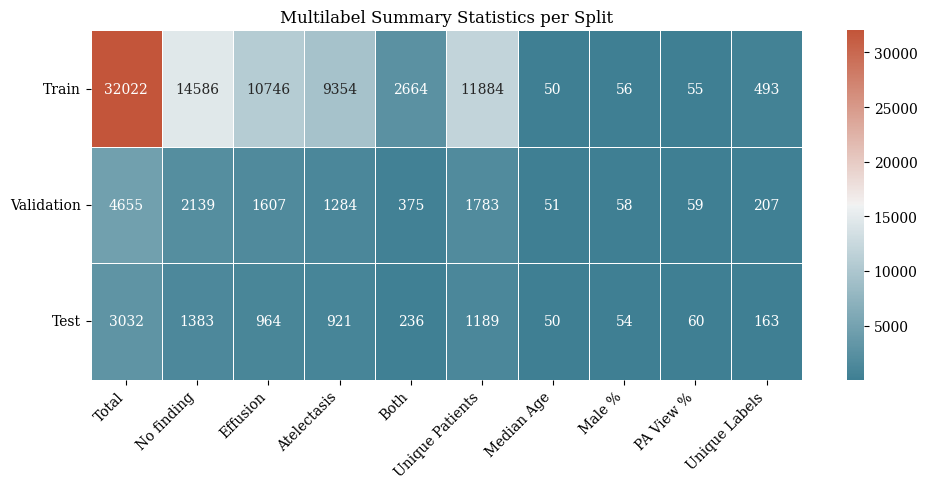
import pandas as pdfrom PIL import Imagefrom tqdm import tqdmfrom rich importprintimport matplotlib.pyplot as pltimport torchvision.transforms as Tfrom torch.utils.data import DataLoaderimport torchvision.transforms.functional as TFfrom CNN import ChestXRayDataset, OUT_DIR# First method: manual per-image mean/stddef calc_mean_std(img_path: str) ->tuple[float, float]: img = Image.open(img_path).convert("L") img = T.Resize((256, 256))(img) tensor = TF.to_tensor(img) mean = tensor.mean().item() std = tensor.std().item()return mean, stddf = pd.read_csv(OUT_DIR /"ml_train.csv")means = []stds = []for img_path in tqdm(df["IMGPATH"], desc="Computing mean and std (method 1)"): mean, std = calc_mean_std(img_path) means.append(mean) stds.append(std)avg_mean =sum(means) /len(means)avg_std =sum(stds) /len(stds)# Second method: dataset-wide mean/std via DataLoader devided by 32 batchestrain_dt = ChestXRayDataset(OUT_DIR /"ml_train.csv", transform=False)def compute_mean_std(dataset): loader = DataLoader(dataset, batch_size=32, shuffle=False) psum =0.0 psum_sq =0.0 count =0for imgs, _ in tqdm(loader, desc="Computing mean and std (method 2)"): imgs = imgs.float().cpu() psum += imgs.sum().item() psum_sq += (imgs **2).sum().item() count += imgs.numel() mean = psum / count std = ((psum_sq / count) - (mean **2)) **0.5return mean, stdmean2, std2 = compute_mean_std(train_dt)print(f"\nMethod 1 - Average mean: {avg_mean:.5f}, Average std: {avg_std:.5f}")print(f"Method 2 - Mean: {mean2:.5f}, Std: {std2:.5f}")# View one sample imageimg, label = train_dt[0]plt.imshow(img.squeeze(0), cmap='gray')plt.title(f"Label: {label}")plt.axis('off')plt.show()
Computing mean and std (method 1): 100%|██████████| 32022/32022 [04:33<00:00, 117.02it/s]
Computing mean and std (method 2): 100%|██████████| 1001/1001 [04:34<00:00, 3.65it/s]
Method 1 - Average mean: 0.49765, Average std: 0.22854