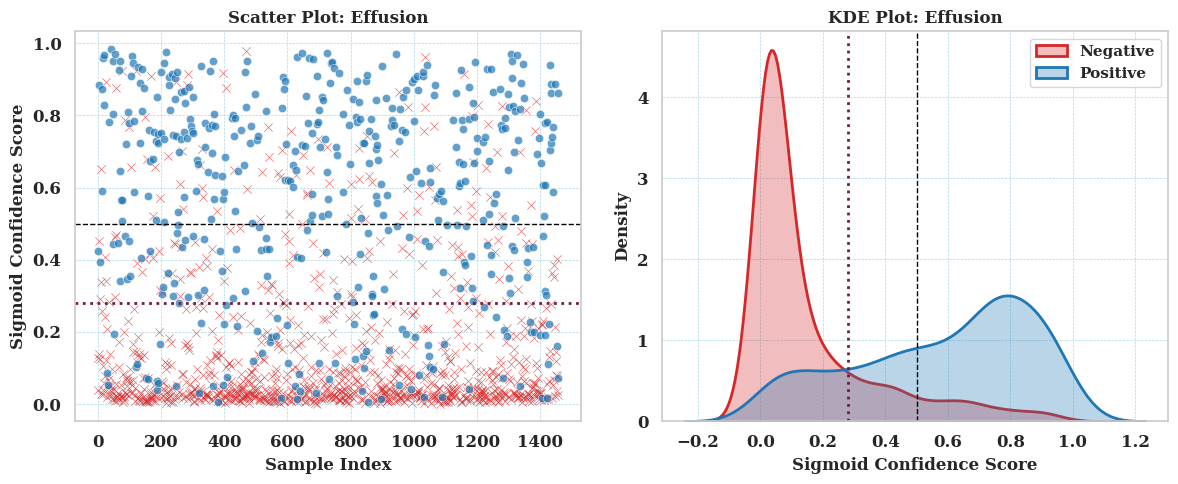
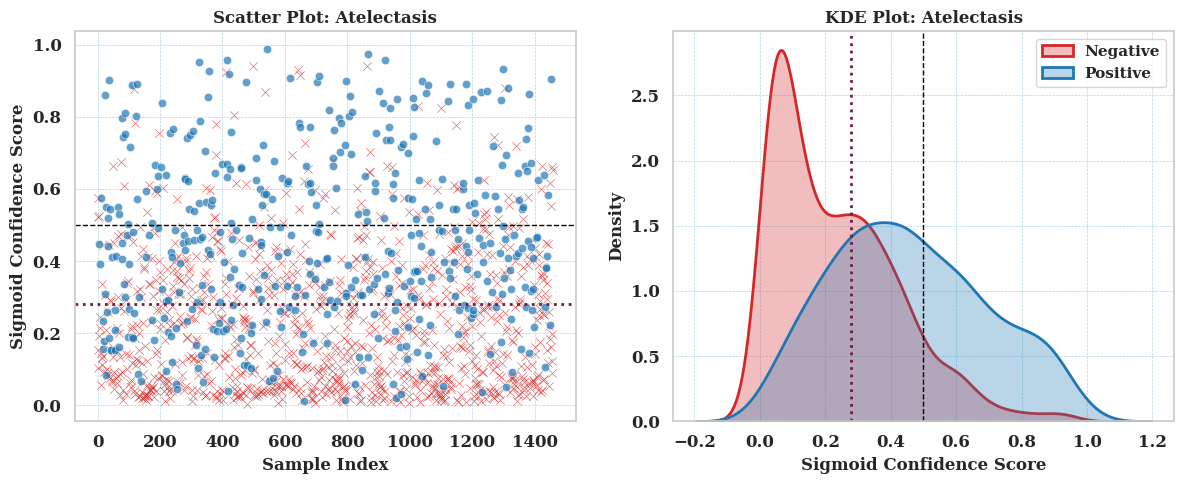
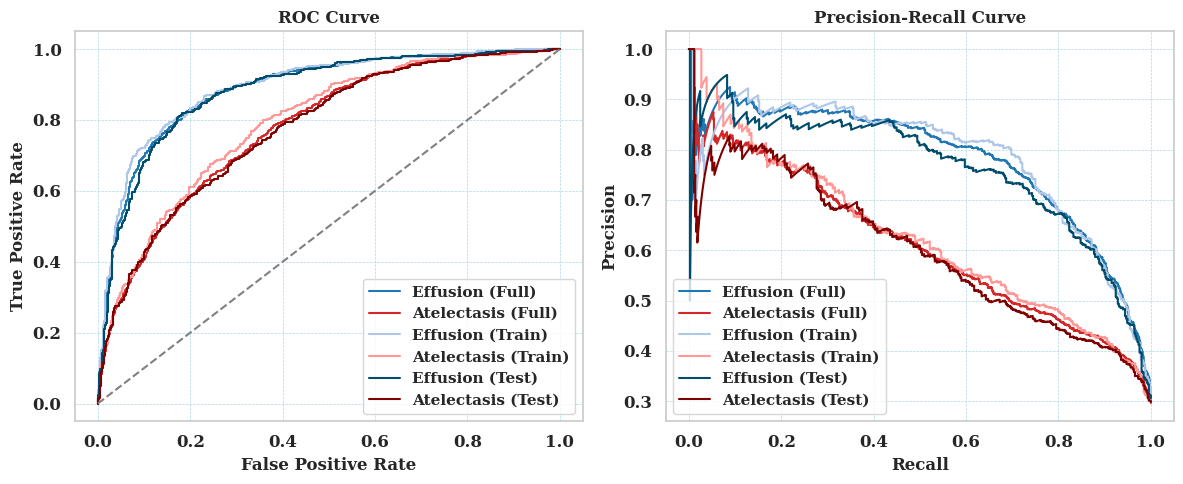
This evaluation compares the decision utility of the CNN and Inferno, both operating on raw logits. For the CNN, utility is assessed using two thresholds: the commonly used default and a threshold optimized on the same training set that was used to train the Inferno model. Inferno’s utility is derived from its calibrated probabilistic output. All comparisons are conducted using a fixed utility matrix, constructed based on findings from clinical research literature.
🧪 Confusion Matrix Comparison and Performance Summary
📋 Combined Confusion Matrices for CNN & Inferno
Model
Threshold
Disease
TP
FP
FN
TN
CNN
0.50
Effusion
285
90
162
922
CNN
0.50
Atelectasis
173
91
261
934
CNN
0.28
Effusion
366
185
81
827
CNN
0.28
Atelectasis
323
371
111
654
Inferno
-
Effusion
351
165
96
847
Inferno
-
Atelectasis
304
356
130
669
📊 Performance Summary
CNN at threshold 0.50 provides a more conservative decision boundary with lower false positives but also higher false negatives, particularly in Atelectasis.
CNN at threshold 0.28 boosts recall significantly (TP increases), but at the cost of many more false positives, especially for Atelectasis.
Inferno offers a well balanced tradeoff between sensitivity and specificity across both diseases: - Outperforms CNN on average utility: 0.9182 vs 0.9077 - Achieves higher TP counts than CNN at 0.50, and fewer FP/FN than CNN at 0.28 - Suggests robust calibration and confidence aware decision making without threshold tuning
✅ Conclusion
Inferno demonstrates improved utility and a more balanced performance profile, making it a compelling option for deployment in scenarios where reliable probabilistic decision making is important. In contrast, CNN provides flexibility through threshold adjustment but depends heavily on careful tuning to manage tradeoffs between sensitivity and specificity.